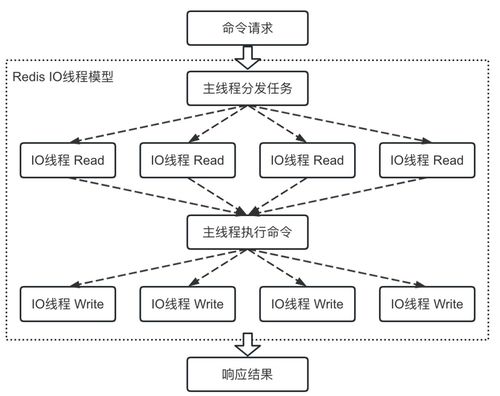
在當(dāng)今大數(shù)據(jù)時代,元數(shù)據(jù)管理已成為企業(yè)數(shù)據(jù)治理的核心環(huán)節(jié),它幫助組織理解、管理和利用海量數(shù)據(jù)。Apache Atlas和Metacat作為兩種主流的元數(shù)據(jù)管理工具,在數(shù)據(jù)處理和存儲服務(wù)方面各有特色。本文將從數(shù)據(jù)處理和存儲服務(wù)的角度,對Atlas和Metacat進行簡要分析和比較。
Apache Atlas是一個開源、可擴展的元數(shù)據(jù)管理和數(shù)據(jù)治理平臺,專為Hadoop生態(tài)系統(tǒng)設(shè)計。在數(shù)據(jù)處理方面,Atlas通過預(yù)定義的鉤子(hooks)自動捕獲元數(shù)據(jù),例如從Hive、Kafka和Sqoop等組件中提取數(shù)據(jù)血緣和分類信息。它支持實時元數(shù)據(jù)更新,并通過REST API允許用戶自定義處理邏輯,增強了數(shù)據(jù)溯源和策略執(zhí)行的靈活性。存儲服務(wù)上,Atlas采用圖數(shù)據(jù)庫(默認使用JanusGraph)來存儲元數(shù)據(jù)實體和關(guān)系,這種結(jié)構(gòu)便于高效查詢復(fù)雜的數(shù)據(jù)血緣圖。它集成了Apache Kafka用于事件通知,確保元數(shù)據(jù)變更的可靠傳播,但存儲層可能面臨性能挑戰(zhàn),需要優(yōu)化圖數(shù)據(jù)庫配置。
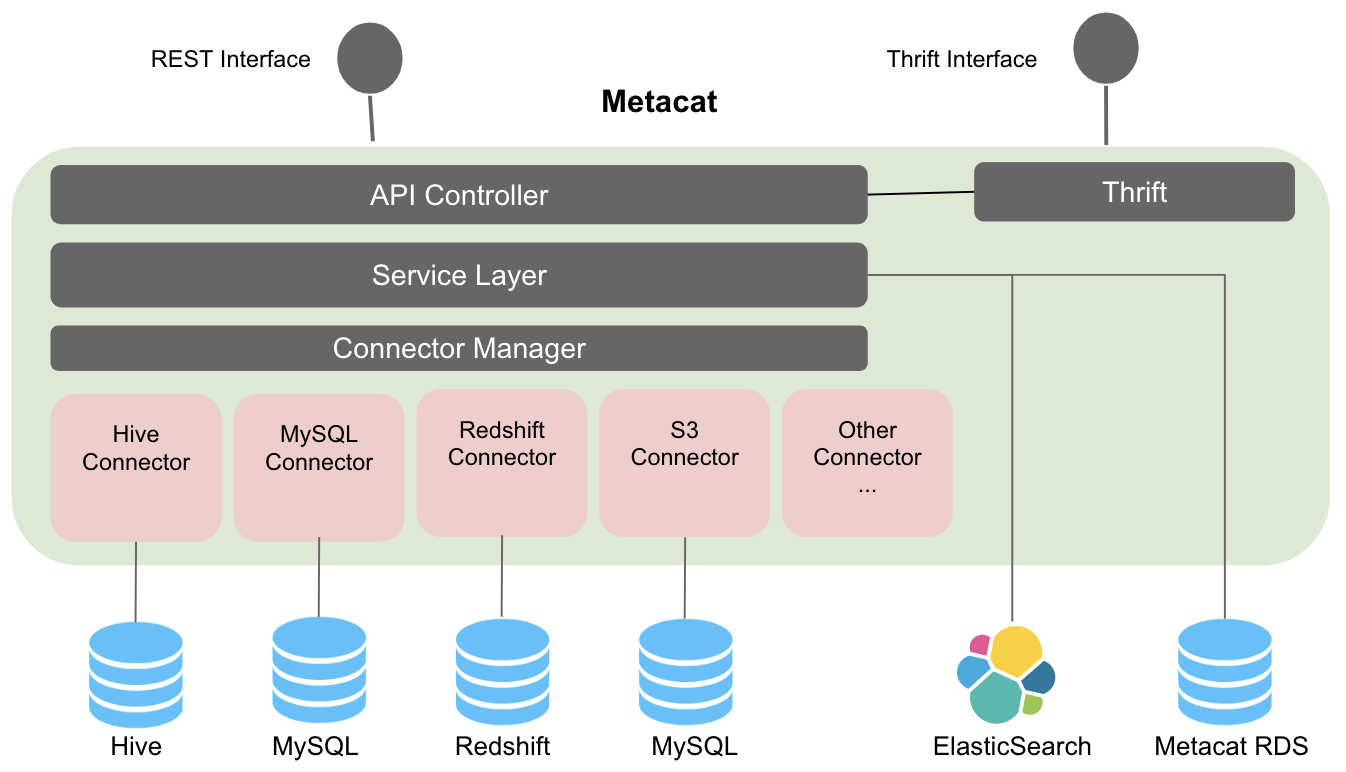
Metacat最初由Netflix開發(fā),后來開源,側(cè)重于解決多數(shù)據(jù)存儲系統(tǒng)的元數(shù)據(jù)統(tǒng)一管理問題。在數(shù)據(jù)處理方面,Metacat通過插件化架構(gòu)支持多種數(shù)據(jù)源(如Hive、S3、RDBMS),能夠集中處理異構(gòu)元數(shù)據(jù),并提供統(tǒng)一的REST接口進行查詢和修改。它強調(diào)數(shù)據(jù)發(fā)現(xiàn)和訪問控制,通過自動分區(qū)管理和數(shù)據(jù)統(tǒng)計收集,提升了數(shù)據(jù)處理的效率。存儲服務(wù)上,Metacat使用關(guān)系型數(shù)據(jù)庫(如MySQL或PostgreSQL)存儲元數(shù)據(jù),這種設(shè)計簡單可靠,易于維護和擴展。它可能不如Atlas在復(fù)雜關(guān)系查詢上靈活,但適合需要穩(wěn)定、統(tǒng)一元數(shù)據(jù)視圖的場景。
Atlas更適合復(fù)雜生態(tài)系統(tǒng)下的數(shù)據(jù)血緣和治理需求,而Metacat則擅長跨數(shù)據(jù)存儲的元數(shù)據(jù)統(tǒng)一管理。企業(yè)在選擇時,應(yīng)根據(jù)自身數(shù)據(jù)處理流程和存儲架構(gòu)來決定:若重視數(shù)據(jù)血緣和實時治理,Atlas是優(yōu)選;若追求多源集成和易用性,Metacat更為合適。隨著云原生和數(shù)據(jù)湖的發(fā)展,兩者都可能進一步優(yōu)化其處理與存儲服務(wù),以支持更廣泛的應(yīng)用場景。