HBase作為分布式、面向列的NoSQL數據庫,在數據處理和存儲服務領域扮演著重要角色。其存儲原理基于Google Bigtable設計思想,融合了HDFS的分布式存儲能力,形成了獨特的層次化結構。本文將通過三張核心示意圖,直觀解析HBase如何高效管理海量數據。
圖一:HBase在Hadoop生態系統中的位置
HBase構建于HDFS之上,如同大廈的地基與樓層關系。HDFS提供底層可靠存儲(數據塊分布式存放),而HBase則在其上構建結構化存儲服務:
- 數據持久化:所有HBase數據最終以HFile格式存儲在HDFS中
- 元數據管理:通過ZooKeeper協調RegionServer狀態與元數據操作
- 讀寫分離:寫操作先寫入Write-Ahead Log (WAL)和MemStore,再刷寫到HDFS;讀操作可合并MemStore和HFile數據
這張圖清晰展示了HBase如何利用Hadoop生態組件實現高可靠、可擴展的存儲基礎。
圖二:HBase的邏輯存儲模型——Sorted Map of Maps
HBase的數據模型可理解為多維有序映射表:
- 行鍵(RowKey):數據檢索主鍵,按字典序排列,決定數據分布
- 列族(Column Family):物理存儲單元,同族數據集中存放(圖中展示CF1、CF2)
- 列限定符(Column Qualifier):動態列標識,支持稀疏存儲
- 時間戳(Version):多版本數據標識,默認保留最新版本
示意圖中,數據按RowKey橫向切分為多個Region,每個Region內數據按列族獨立存儲。這種設計使得:
- 查詢時可通過RowKey快速定位Region
- 同列族數據集中壓縮,提升存儲效率
- 支持數億列的海量稀疏表存儲
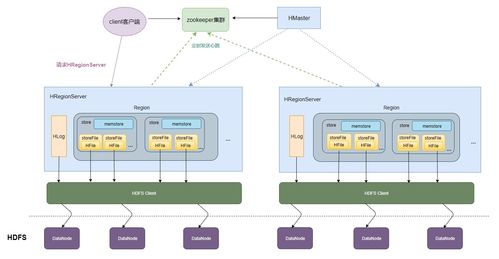
圖三:HBase物理存儲架構——RegionServer與StoreFile
這是最關鍵的存儲實現圖,展示數據在RegionServer中的物理組織:
- Region分割:每張表按RowKey范圍劃分為多個Region,分配到不同RegionServer
- Store結構:每個Region包含多個Store(對應列族),每個Store包含:
- MemStore:內存寫緩沖區,排序后數據
- StoreFile:磁盤存儲文件(HFile格式),由MemStore刷寫生成
- Compaction機制:
- Minor Compaction:合并多個小StoreFile
- Major Compaction:合并所有StoreFile并清理過期數據
圖中箭頭清晰展示了數據流向:
- 寫入路徑:Client → WAL → MemStore → 定期刷寫為StoreFile
- 讀取路徑:Client → MemStore + StoreFiles → 合并返回結果
- 壓縮流程:多個StoreFile → 合并為更大StoreFile → 減少IO開銷
數據處理服務的關鍵特性
基于上述存儲原理,HBase提供三大核心服務能力:
- 強一致性讀寫
- 單行事務保證原子性
- 通過RegionServer主節點協調數據訪問
- WAL機制確保寫入不丟失
- 自動分片與負載均衡
- Region達到閾值時自動分裂
- Master服務監控并平衡Region分布
- 支持在線擴展,無需停機
- 高效數據生命周期管理
- TTL(生存時間)自動清理過期數據
- 多版本數據保留策略配置
- Bloom Filter加速不存在鍵的判斷
存儲優化實踐建議
- RowKey設計策略
- 避免單調遞增,采用散列前綴防止熱點
- 將查詢維度前置,利用字典序優化范圍查詢
- 長度控制在10-100字節,減少存儲開銷
- 列族配置要點
- 數量不宜過多(通常2-3個),每個列族獨立存儲
- 根據訪問模式設置不同壓縮算法(SNAPPY/LZ4)
- 合理設置內存緩存優先級
- 集群部署考量
- RegionServer與DataNode協同部署,減少網絡傳輸
- 預留20%磁盤空間供Compaction使用
- 監控StoreFile數量,觸發閾值告警
通過這三張圖,我們完整理解了HBase如何將邏輯數據模型映射到物理存儲:從HDFS基礎存儲,到Region分布式管理,再到MemStore與StoreFile的讀寫優化。這種層次化設計使得HBase能夠支撐從千萬到百億級數據量的實時讀寫場景,成為大數據存儲領域不可或缺的基礎服務。
掌握這些核心原理后,在實際應用中還需結合具體業務特點調整配置參數,并通過監控系統持續觀察Region分布、Compaction頻率等關鍵指標,才能充分發揮HBase在數據處理和存儲服務中的強大能力。